

Quantization Made Simple: How to Run Big Models on Small Hardware?
Learn what quantization is and how it works

When I worked in the healthcare domain, we faced a problem that probably sounds familiar to many of you. We needed to deploy a Large Language Model (LLM), but because of data privacy, everything had to stay on our client’s hardware. No cloud APIs. No external servers. Just us and their single GPU with 16GB of memory. Our specialized LLM had 8 billion parameters. The math was simple and brutal. It wouldn’t fit.
Through a technique called quantization, we managed to run that model smoothly on hardware that should have been too small. This post will help you understand what makes LLMs so demanding on memory, what quantization actually does to solve this problem, and how it manages to shrink models without breaking them. So let’s get into it!
Before continuing, take a look at this article to get a better understanding of how LLMs work.
Why You Should Care About This
LLMs are getting absurdly large. Some models now have hundreds of billions of parameters, with the largest reaching into the trillions. Even the “small” 7-billion-parameter models need significant hardware to run. This creates real problems! Renting GPUs with enough memory gets expensive fast. Not everyone can or wants to use cloud APIs. Developers want to run models locally on their laptops. Like our healthcare case, some data simply cannot leave the building due to privacy requirements.
Quantization offers a solution. This technique can cut your memory requirements in half or even to a quarter with barely any performance loss. That 16GB model can run on 8GB, sometimes even 4GB.
The Big Picture: What is Quantization?
Before we dive into the mechanics, let me give you an intuitive understanding of what we’re trying to achieve. Think about photos on your phone. You could store every picture in maximum quality RAW format, but that’s impractical. Instead, your phone compresses them to JPG. The files are 10x smaller, yet you barely notice the difference when viewing them.
Quantization does the same thing for LLMs. In simple terms:
Quantization reduces the precision of the numbers that make up your model, making it smaller while maintaining its performance.
It’s a compression technique, but instead of compressing pixels, we’re compressing the mathematical weights that power the model.
How Numbers Work in LLMs
To understand quantization, you need to know just one thing. Everything in a neural network comes down to numbers, billions of them. These numbers are called parameters or weights, and they represent what the model learned during training. They determine how the model processes your input and generates output. Each number is stored in computer memory using bits, which are just 0s and 1s. The more bits you use, the more precise the number becomes, but it also consumes more memory.
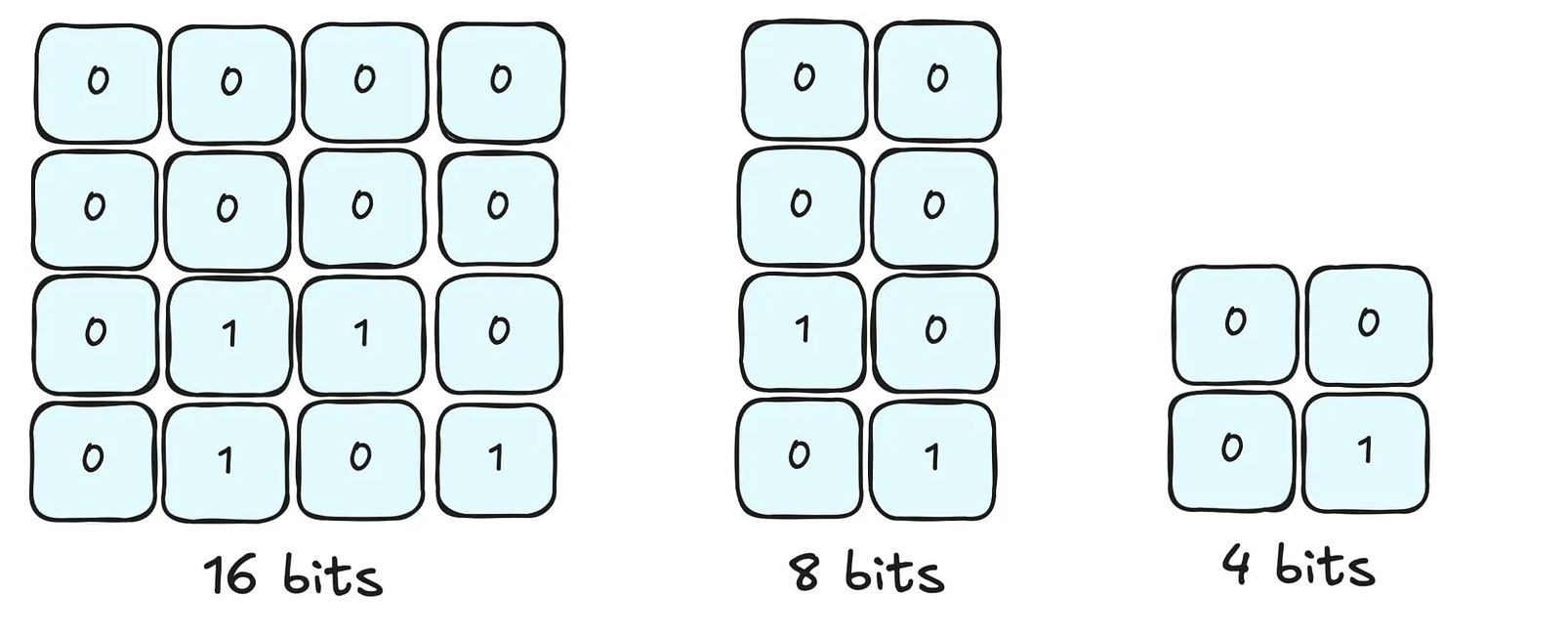
Modern LLMs typically use three different precision levels. The first is 16 bits (2 bytes), which is the standard training precision for most models. The second is 8 bits (1 byte), which is a common quantization target that provides 50% memory reduction and 1.56x speed up. The third is 4 bits (0.5 bytes), which is a more aggressive quantization that provides 75% memory reduction.
The Memory Math Made Simple
To understand how much memory is required to run an LLM, this is the most important formula you’ll need.

Let’s apply this to a real example with Llama 2 7B. With 16-bit precision, you need 7 billion parameters multiplied by 2 bytes, which equals 14 GB. With 8-bit quantization, you need 7 billion parameters multiplied by 1 byte, which equals 7 GB. With 4-bit quantization, you just need 3.5 GB. Same model, drastically different memory footprint.
During inference, when the model is generating text, you need extra memory for something called KV-cache. This cache stores context from the conversation.
The amount of extra memory depends on size of your context window.
Larger context windows, like 8K or 32K tokens, need significantly more memory than smaller ones like 2K or 4K tokens. For a 7B model in 8-bit with a typical 4K context window, you should plan for around 9GB of VRAM. If you’re tight on VRAM, you can reduce the context window to make the model fit.
How Quantization Actually Works
Now let’s peek under the hood and see what’s actually happening when we quantize a model. I promise to keep it simple, but understanding this will help you make better decisions about when and how to use quantization.
The core idea is that we’re mapping high-precision numbers to low-precision numbers.
Imagine you have a thermometer that measures temperature to the tenth of a degree, showing readings like 68.4°F, 68.8°F, and 69.9°F. Quantization is like switching to a thermometer that only shows whole numbers like 68°F, 69°F, and 70°F. You lose some detail, but you still get useful information.
A Simple Example
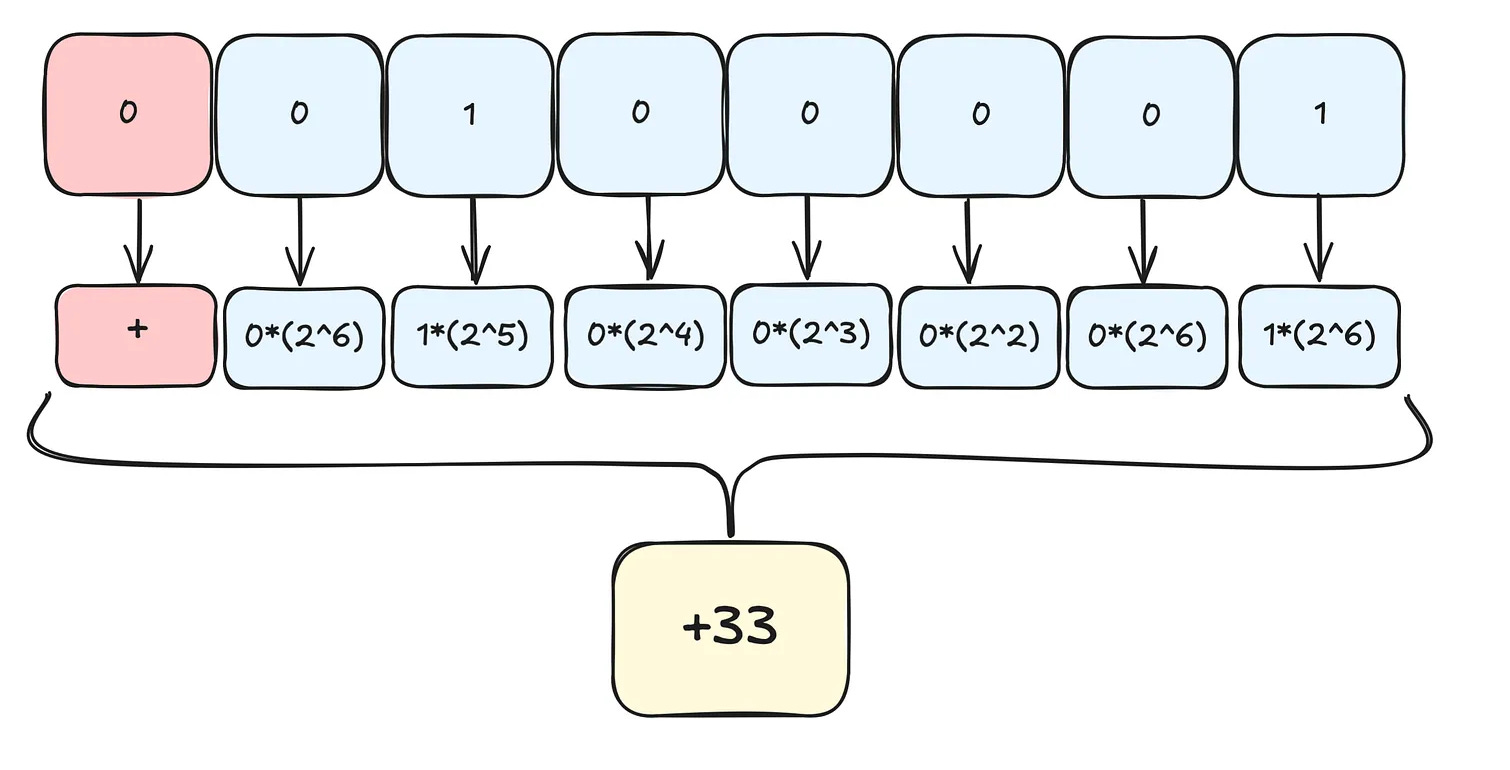
Let me show you how this works with a concrete example. Let’s say we want to quantize the number 33 from 8-bit to 4-bit representation.
In 8-bit space, numbers range from -128 to 127, giving us 256 possible values. In 4-bit space, numbers range from -8 to 7, giving us only 16 possible values. To convert between them, we need a scale factor.
The scale factor is calculated by dividing 256 by 16, which gives us 16. Now we can quantize our number. We take 33 and divide it by 16, which gives us 2.0625. After rounding, we get 2.
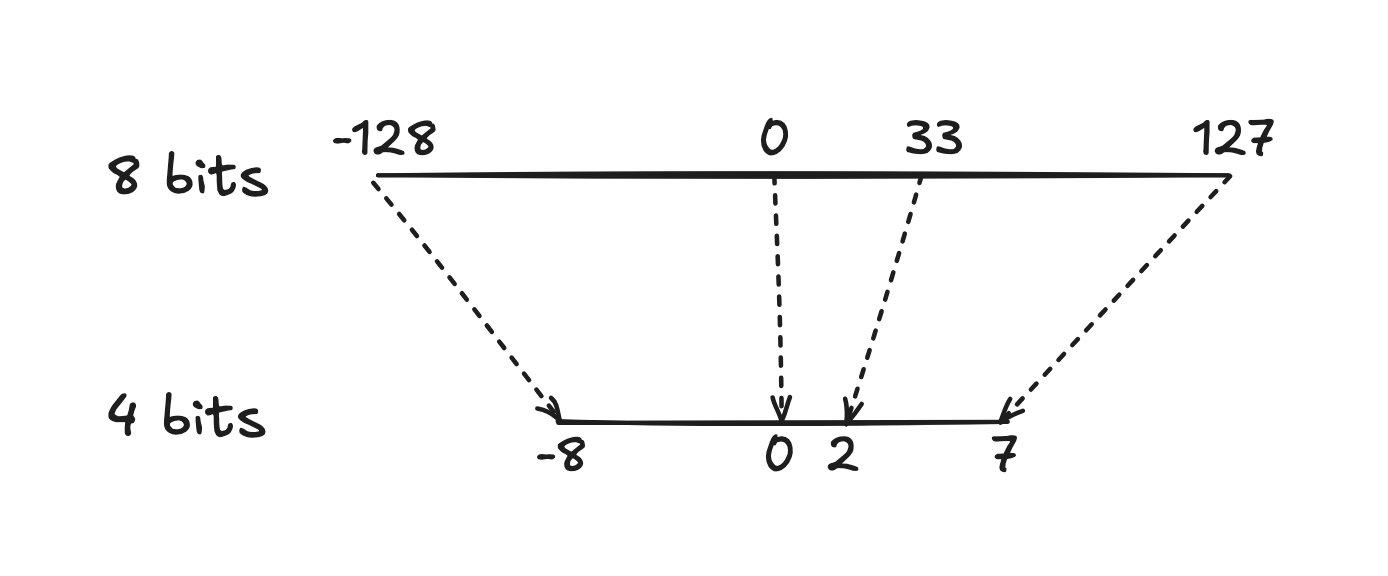
So the number 33 in 8-bit becomes 2 in 4-bit. When we need to use it again, we scale it back up by multiplying 2 by 16, which gives us 32. We lost a tiny bit of precision because 33 became 32, but we saved 50% of the memory.
This process happens for every single weight in the model, billions of times over. The accumulated small losses in precision are what lead to that minimal performance degradation I mentioned earlier.
To learn how different quantization techniques work in more detail, I recommend reading this article by Maarten Grootendorst.
Why This Doesn’t Break Your Model
You might be wondering why losing precision on billions of numbers doesn’t make the model terrible. The answer lies in how neural networks actually work.
LLMs are surprisingly robust to small amounts of noise.
They are extremely well optimized during training, so that they actually learn to be noise-resistant. This built-in resilience is what makes quantization possible without destroying performance.
Additionally, researchers use clever techniques to minimize the impact. Asymmetric quantization adjusts the mapping to better fit the actual distribution of weights. Per-channel quantization uses different scale factors for different parts of the model. Mixed precision keeps critical layers in higher precision while quantizing others more aggressively.
You don’t need to implement these techniques yourself because they’re built into modern quantization tools.
Common Quantization Formats
When you go looking for quantized models, you’ll see several formats. Understanding what they mean will help you choose the right one for your needs.
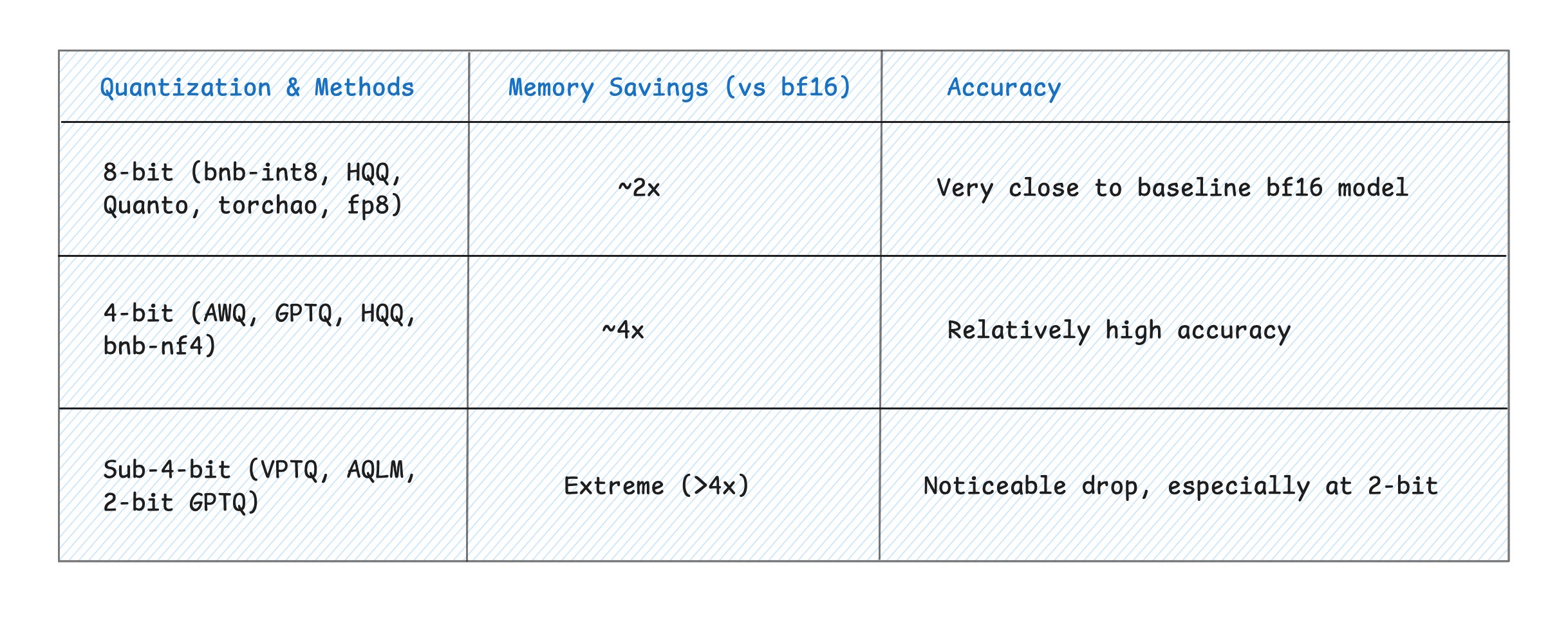
INT8 and Q8_0 refer to 8-bit integer quantization. This format provides 50% memory reduction with 99% or better performance retention. It’s best for production deployments where you want maximum safety and reliability.
GPTQ is a 4-bit quantization method that provides 75% memory reduction with 98% performance retention. It’s optimized for GPU inference and works best when you’re trying to run larger models on consumer hardware.
GGUF (formerly called GGML) is a flexible quantization format that supports anywhere from 2 to 8 bits. You’ll see various formats like Q4_K_M, Q5_K_S, and Q8_0. This format is optimized for CPU and Apple Silicon inference and powers popular tools like Ollama and LM Studio.
Performance Expectations
Different quantization levels give you different trade-offs between size and quality. With 8-bit quantization using INT8, you’ll barely notice any difference. I mean it when I say the performance is virtually identical to the original model.
With 4-bit quantization like Q4, you might see a slight quality reduction in very specific edge cases, but most users won’t notice in typical usage. With 3-bit or lower quantization, you’ll see noticeable quality degradation, so only use these formats if you’re desperate for memory.
The sweet spot for most people is 8-bit for critical production use and 4-bit for experimentation and local development.
Your Action Plan
Rule #1: Always Use 8-bit When Running Locally
If you’re deploying an LLM on your own, there’s no reason not to use 8-bit quantization. The performance difference is negligible, and you’ll save 50% on memory costs. It’s essentially free optimization.
Rule #2: Calculate Before You Download
Before pulling a model, you should check whether it’ll actually fit on your hardware. First, find the parameter count, which is usually in the model name like “Llama-2-7b” or “Mistral-7B”. Next, decide on your quantization level. Then apply the formula I showed you earlier. Finally, add a 20% buffer for KV-cache to be safe.
Quick Reference Table:
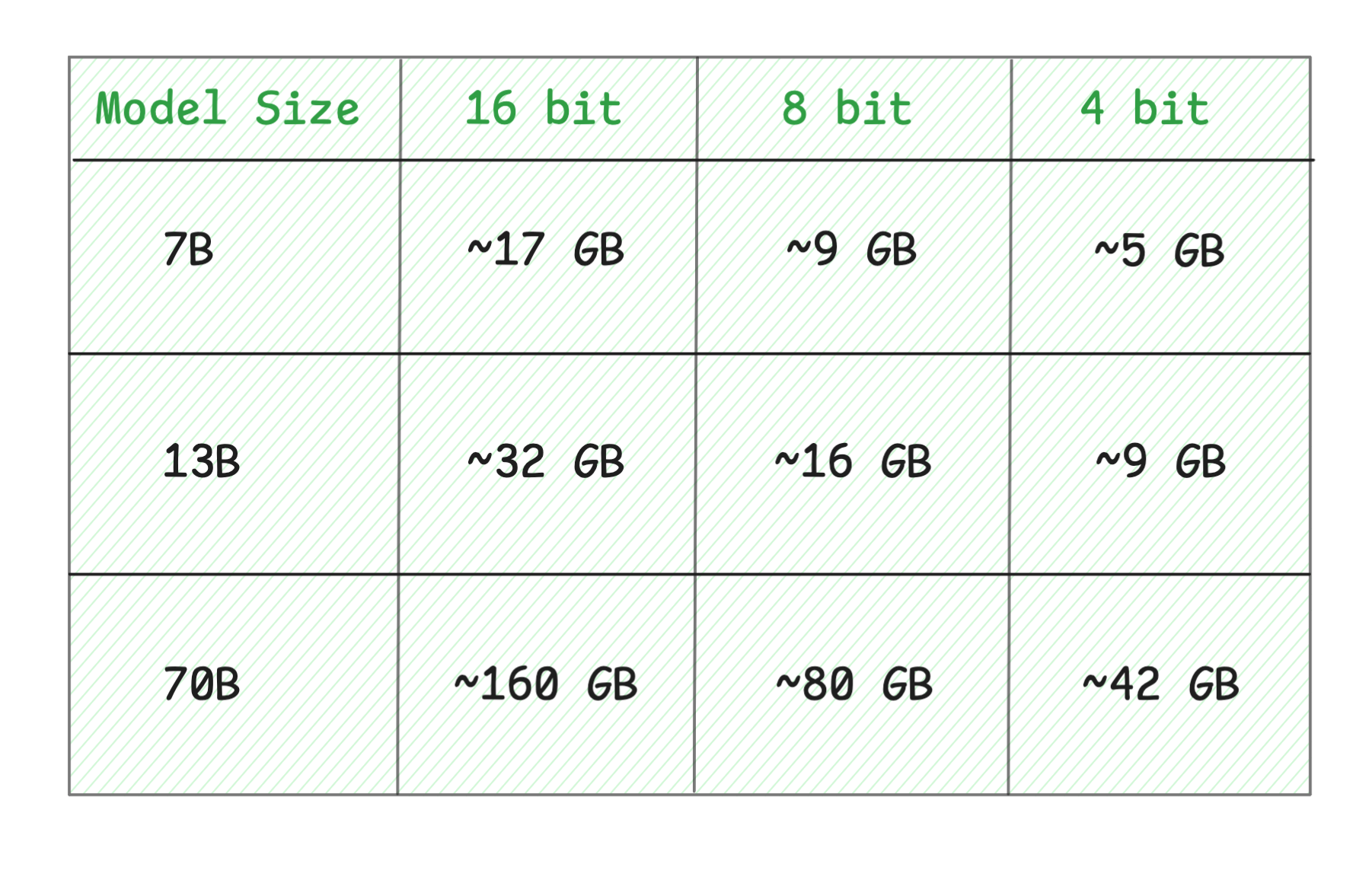
These estimates assume a 4K token context window. Larger context windows (8K, 32K, etc.) will require additional memory. If you’re constrained by VRAM, you can reduce the context window to fit your hardware.
Rule #3: Where to Find Quantized Models
You have two main options for getting quantized models.
Option 1 is using pre-quantized models on Hugging Face. Most popular models already have pre-quantized versions available. You can search for the model name plus “GPTQ” if you need GPU inference, or the model name plus “GGUF” if you need CPU or Mac inference. For example, instead of searching for “meta-llama/Llama-2-7b-hf”, you would search for “TheBloke/Llama-2-7B-GPTQ”.
Option 2 is quantizing the model yourself if you have a custom model or can’t find what you need. For GPTQ format, you can use the AutoGPTQ library. For GGUF format, you can use the llama.cpp conversion tools. For general quantization, you can use llm-compressor by vLLM.
Most tools require just a single command to quantize your model:
# Example with llm-compressor
llmcompressor quantize your-model --format int8Rule #4: Test Before You Commit
Before deploying a quantized model, you should run your specific use cases through it. Create a small test set that includes typical queries you expect, edge cases that matter to your application, and quality metrics you care about.
Compare the quantized version against the original. In most cases with 8-bit, you’ll see identical results. With 4-bit, you might see tiny differences that you need to evaluate for your use case.
Wrapping up
Quantization isn’t a hack or a workaround. It’s a fundamental technique that makes LLMs accessible. It’s the reason you can run powerful models on consumer hardware. It’s why small teams can compete with big labs on deployment. It’s how that healthcare project actually shipped.
“Quantization is an essential tool for optimizing LLMs in real-world deployments.”
There are a few key points you should remember:
First, 8-bit quantization is practically free performance-wise, so use it by default.
Second, memory needed equals the billions of parameters multiplied by bytes per weight, multiplied by 1.2 for safety.
Third, most quantized models are pre-made and ready to download.
Fourth, when in doubt, try it because you can always go back to higher precision if needed.
The world of AI is moving fast, but it’s also becoming more accessible.
You don’t need a server farm to run state-of-the-art models anymore. You just need to know how to make them fit.
Now go make that model run on your hardware.
Have questions about quantization or want to share your own deployment story? Comment below and I will respond to every question.